
- Home
- Industries
 Aerospace And Defence
Aerospace And Defence
 Agriculture
Agriculture
 Automotive And Transportation
Automotive And Transportation
 Banking And Finance
Banking And Finance
 Business
Business
 Chemicals And Materials
Chemicals And Materials
 Consumer And Retail
Consumer And Retail
 Electronics And Semiconductors
Electronics And Semiconductors
 Food And Beverages
Food And Beverages
 Machinery & Equipments
Machinery & Equipments
 Manufacturing And Construction
Manufacturing And Construction
 Medical Devices
Medical Devices
 Others
Others
 Pharmaceuticals And Healthcare
Pharmaceuticals And Healthcare
 Power And Energy
Power And Energy
 Sports
Sports
 Technology
Technology
- Services
- News Room
- About us
- Contact Us
-
AI Training Dataset Market Size, Trends & Forecast| 24.2% CAGR
Global AI Training Dataset Market Size, Share & Analysis By Type (Text, Image & Video, Audio), By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others), Data Quality Trends, Vendor Landscape & Forecast 2025–2034

Report Overview
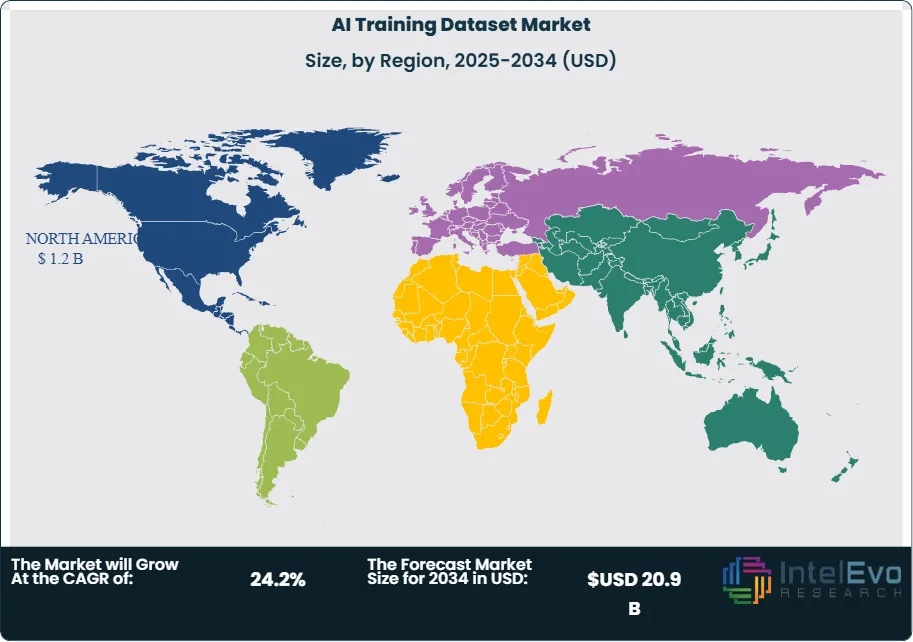
The AI Training Dataset Market is estimated at USD 3.6 billion in 2024 and is on track to reach roughly USD 20.9 billion by 2034, implying a compound annual growth rate of 24.2% over 2024–2034. Following an early phase defined by pilot AI deployments and fragmented data sourcing, the market has entered a scale-up era as enterprises industrialize machine learning pipelines. Spend is expanding from narrow text corpora toward multimodal assets—image, audio, video, sensor, and tabular—reflecting the shift from experimentation to production-grade AI. North America led in 2024 with a 35.5% revenue share (USD 0.9 billion), supported by deep AI budgets and mature data governance, while Asia–Pacific is set to post the fastest growth as digital-first economies expand data creation and localization capabilities.

Get More Information about this report -
Request Free Sample ReportDemand-side drivers include the proliferation of generative AI, the embedding of AI in customer service, risk, and operations, and sector-specific use cases such as clinical documentation, autonomous systems, fraud prevention, and supply-chain forecasting. On the supply side, the market benefits from rapid advances in data engineering: automated labeling and QA, data versioning and lineage, and synthetic data generation to amplify scarce or sensitive classes. Enterprises increasingly prioritize dataset quality over sheer volume; initiatives to reduce bias, improve representativeness, and enhance edge-case coverage are becoming budget line items, not afterthoughts. At the same time, costs for large-scale collection and curation remain material, and access to rights-cleared content is a gating factor.
Regulation is both catalyst and constraint. Intensifying privacy and data-sovereignty regimes, alongside emerging AI governance frameworks, are elevating the premium on auditable, licensed, and jurisdiction-compliant datasets. Vendors that can document provenance, consent, and model-ready formatting are gaining share. Key risks include copyright disputes, demographic skew in source data, domain drift as real-world conditions change, and security exposures when handling sensitive information.
Technological innovation will shape adoption through data-centric AI practices, active learning to target high-impact samples, weak supervision to speed annotation, and privacy-preserving techniques such as federated learning and differential privacy. Investment hotspots include domain-specific and multilingual datasets, healthcare-grade and safety-critical corpora for automotive and robotics, and platforms that blend synthetic with real-world data to accelerate model generalization. Europe is emerging as a hub for regulated-industry datasets, while India, Southeast Asia, and the Middle East present outsized opportunities in localized, low-resource language assets.
, By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others), Data Quality Trends, Vendor Landscape & Forecast 2025–2034")
Key Takeaways
- Market Growth: The global AI Training Dataset Market is set to expand from USD 3.6 billion in 2024 to USD 20.9 billion by 2034, a 24.2% CAGR (2025–2034), propelled by generative AI scale-up, multimodal model training, and enterprise data-centric AI practices. The period adds ~USD 16.3 billion in incremental spend, underscoring a rapidly deepening TAM.
- By Data Type: Image/Video datasets led in 2024 with 41.2% share, reflecting computer vision, autonomous systems, and multimodal LLM demand. Continued investment in edge-case coverage and safety-critical annotations positions this segment to remain the largest revenue contributor through the forecast horizon.
- By End Use: Information Technology (IT) accounted for >34% of 2024 revenue, supported by hyperscalers and platform providers operationalizing data pipelines across cloud and MLOps stacks (e.g., AWS, Microsoft, Google Cloud). IT’s scale advantages in tooling, governance, and spend aggregation reinforce its leadership in dataset procurement.
- Driver: The surge in generative and multimodal AI is expanding dataset breadth and quality requirements, evidenced by North America’s USD 0.9 billion spend and 35.5% share in 2024 and the U.S. market rising from USD 0.69 billion (2024) to USD 0.81 billion (2025) on its way to USD 3.58 billion (2034). Enterprises are prioritizing balanced, representative corpora to reduce bias and improve model generalization.
- Restraint: Rights-cleared content access, privacy compliance, and rising curation costs are tempering near-term velocity—illustrated by the U.S. market’s 17.9% CAGR lagging the global 22.2%, implying governance and maturity headwinds. Concentration in North America (35.5% share) also heightens exposure to regulatory shifts.
- Opportunity: Outside North America, regions collectively contributed ~USD 1.7 billion in 2024 and are poised to capture a sizable share of the ~USD 16.3 billion global expansion to 2034. High-growth pockets include multilingual, healthcare-grade, and safety-critical automotive/robotics datasets, where premium pricing and compliance credentials command outsized margins.
- Trend: Procurement is shifting from volume to quality, with data-centric techniques (active learning, QA automation, synthetic augmentation) compressing iteration cycles; the U.S. market is set to grow ~5.2× from 2024 to 2034 (USD 0.69→3.58 billion). Multimodal training remains pivotal, anchoring Image/Video’s 41.2% 2024 lead.
- Regional Analysis: North America leads with 35.5% share and USD 0.9 billion in 2024; the U.S. alone advances at 17.9% CAGR to USD 3.58 billion by 2034. Regions beyond North America (combined ~USD 1.7 billion in 2024) are expected to grow at or above the global pace (22.2% CAGR), gradually increasing their contribution to global revenue.
Type Analysis
The market continues to pivot toward multimodal training corpora, yet Image/Video remains the anchor category. After commanding ~41.2% share in 2024, Image/Video datasets are projected to retain a ~40–42% mix in 2025 as enterprises scale perception models for autonomous systems, retail analytics, security, and immersive media. Higher-resolution streams (4K/8K) and longer-sequence video push demand for densely annotated scenes, long-tail edge cases, and scenario libraries—driving premium pricing for rights-cleared content and specialized labeling. Text corpora remain foundational for large language models (LLMs), but procurement increasingly favors provenance-attested, domain-rich, and instruction/feedback datasets that improve factuality and safety.
Audio is poised to be the fastest-growing type through 2025–2030 (low-to-mid-20s % CAGR), propelled by contact-center modernization, multilingual assistants, and on-device speech models. Growth is concentrated in diarization, emotion intent tagging, and low-resource languages—often blended with synthetic augmentation to fill gaps. Across types, automation is compressing cycle times: active learning, weak supervision, and quality assurance (QA) at scale can trim labeling costs by 15–25%, improving return on dataset spend as volumes rise.
Application Analysis
Computer Vision (CV) remains the largest application by spend, aligned with Image/Video’s share and expected to command ~45–50% of training dataset outlays in 2025. Key demand pools include automotive ADAS and autonomous driving (object detection, segmentation, depth), physical retail (loss prevention, shelf analytics), logistics (defect and damage detection), and public safety. Healthcare imaging—radiology, pathology, ophthalmology—adds durable, compliance-intensive demand for expertly curated and bias-audited images.
Natural Language Processing (NLP) is expanding from general-purpose web text to enterprise-grade instruction, RAG (retrieval-augmented generation), and alignment datasets. 2025 priorities include domain specialization (legal, financial, clinical), multilingual expansion, and safety tuning, lifting NLP’s share to the mid-30s%. Speech & Audio—roughly a mid-teens % share—benefits from omnichannel support workflows and real-time translation, with growth strongest in multilingual and accented speech collections. Multimodal applications that blend text, vision, and audio (e.g., VLMs for agentic workflows) are set to capture outsized budget increases as enterprises pilot end-to-end automation.
End-Use Analysis
Information Technology (IT) retains leadership (>34% share in 2024) and is expected to remain the largest buyer in 2025 as hyperscalers, platform vendors, and AI-native startups expand data pipelines, governance, and evaluation suites. Investment focuses on scalable annotation, lineage, and licensing frameworks to meet enterprise procurement standards. Automotive is among the fastest growers (often >25% CAGR in 2025–2030 estimates), driven by sensor fusion, long-horizon prediction, and safety validation that require massive, diverse video logs and rare-event libraries.
Healthcare and Life Sciences are accelerating (mid-20s % CAGR outlook) as payers/providers adopt imaging, documentation, and clinical NLP; demand concentrates on de-identified, consented, and demographically representative datasets. BFSI prioritizes fraud, AML, underwriting, and conversational agents—favoring high-quality tabular, text, and voice data with strict audit trails. Retail & E-commerce continues to scale computer vision and personalization, while Government demand centers on multilingual, low-resource, and domain-specific corpora under stringent sovereignty rules.
Region Analysis
North America remains the largest regional market (35.5% share; ~USD 0.9 billion in 2024) and is projected to exceed USD 1.1–1.2 billion in 2025, supported by deep AI budgets, mature data governance, and active model risk management. The U.S. alone is on a ~17.9% CAGR path toward ~USD 3.6 billion by 2034, with continued outlays for rights-cleared, provenance-documented content and sophisticated evaluation sets. Europe is scaling steadily (low-20s % CAGR), with GDPR, AI Act–aligned sourcing, and sectoral codes of conduct increasing demand for auditable, bias-tested datasets—particularly in healthcare, financial services, and regulated public-sector use cases.
Asia Pacific is the fastest-growing region (often mid-20s % CAGR), underpinned by national AI programs, expanding data center footprints, and vibrant ecosystems in China, India, Japan, and Southeast Asia. Growth concentrates on multilingual, low-resource languages, and edge AI for manufacturing and mobility. Latin America and the Middle East & Africa are at earlier stages but show double-digit growth trajectories as governments digitize services and enterprises modernize contact centers and payments. Across all regions, sovereignty, licensing clarity, and demographic representativeness are emerging as decisive procurement criteria, shaping vendor selection and long-term partnerships.
Get More Information about this report -
Request Free Sample ReportMarket Key Segments
By Type
- Text
- Image & Video
- Audio
By Vertical
- IT
- Automotive
- Government
- Healthcare
- BFSI
- Retail & E-commerce
- Others
Regions
- North America
- Latin America
- East Asia And Pacific
- Sea And South Asia
- Eastern Europe
- Western Europe
- Middle East & Africa
| Report Attribute | Details |
| Market size (2024) | USD 3.6 B |
| Forecast Revenue (2034) | USD 20.9 B |
| CAGR (2024-2034) | 24.2% |
| Historical data | 2020-2023 |
| Base Year For Estimation | 2024 |
| Forecast Period | 2025-2034 |
| Report coverage | Revenue Forecast, Competitive Landscape, Market Dynamics, Growth Factors, Trends and Recent Developments |
| Segments covered | By Type (Text, Image & Video, Audio), By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others) |
| Research Methodology |
|
| Regional scope |
|
| Competitive Landscape | Google, Amazon Web Services (AWS), Microsoft, Appen, Scale AI, Alegion, Deep Vision Data, Cogito Tech, Lionbridge, Samasource (Sama) |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Pricing and Purchase Options | Avail customized purchase options to meet your exact research needs. We have three licenses to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF). |
, By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others), Data Quality Trends, Vendor Landscape & Forecast 2025–2034")
, By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others), Data Quality Trends, Vendor Landscape & Forecast 2025–2034")
, By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others), Data Quality Trends, Vendor Landscape & Forecast 2025–2034")
Frequently Asked Questions
How big is the AI Training Dataset Market?
The AI Training Dataset Market will rise from USD 3.6B in 2024 to USD 20.9B by 2034, driven by multimodal data demand, enterprise-scale ML adoption, and strong growth in North America and APAC.
Who are the major players in the AI Training Dataset Market?
Google, Amazon Web Services (AWS), Microsoft, Appen, Scale AI, Alegion, Deep Vision Data, Cogito Tech, Lionbridge, Samasource (Sama)
Which segments covered the AI Training Dataset Market?
By Type (Text, Image & Video, Audio), By Vertical (IT, Automotive, Government, Healthcare, BFSI, Retail & E-commerce, Others)
How can this market research report help my business make strategic decisions?
Our market research reports provide actionable intelligence, including verified market size data, CAGR projections, competitive benchmarking, and segment-level opportunity analysis. These insights support strategic planning, investment decisions, product development, and market entry strategies for enterprises and startups alike.
How frequently is the data updated?
We continuously monitor industry developments and update our reports to reflect regulatory changes, technological advancements, and macroeconomic shifts. Updated editions ensure you receive the latest market intelligence.

Select Licence Type
Connect with our sales team
Why IntelEvoResearch
100%
Customer
Satisfaction
24x7+
Availability - we are always
there when you need us
200+
Fortune 50 Companies trust
IntelEvoResearch
80%
of our reports are exclusive
and first in the industry
100%
more data
and analysis
1000+
reports published
till date
