
- Home
- Industries
 Aerospace And Defence
Aerospace And Defence
 Agriculture
Agriculture
 Automotive And Transportation
Automotive And Transportation
 Banking And Finance
Banking And Finance
 Business
Business
 Chemicals And Materials
Chemicals And Materials
 Consumer And Retail
Consumer And Retail
 Electronics And Semiconductors
Electronics And Semiconductors
 Food And Beverages
Food And Beverages
 Machinery & Equipments
Machinery & Equipments
 Manufacturing And Construction
Manufacturing And Construction
 Medical Devices
Medical Devices
 Others
Others
 Pharmaceuticals And Healthcare
Pharmaceuticals And Healthcare
 Power And Energy
Power And Energy
 Sports
Sports
 Technology
Technology
- Services
- News Room
- About us
- Contact Us
-
AI Voice Generator Market Size, Share & Growth Outlook | CAGR 14.2%
Global AI Voice Generator Market Size, Share & Analysis By Component (Software, Services), By Deployment Mode (Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning), By End-Use Industry (Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce) Industry Regions & Key Players – Market Structure, Innovation Trends, Competitive Strategies & Forecast 2025–2034

Report Overview
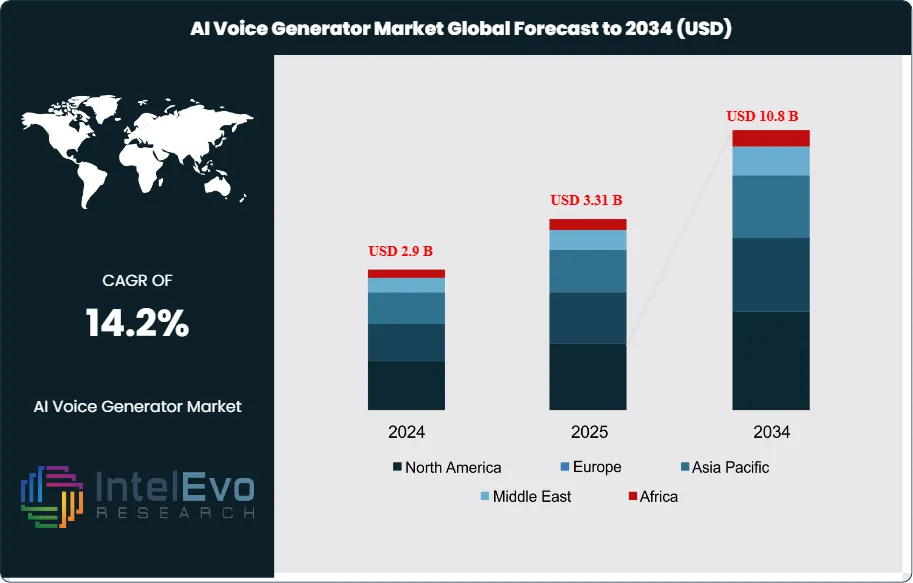
The AI Voice Generator market is valued at approximately USD 2.9 billion in 2024 and is projected to reach nearly USD 10.8 billion by 2034, registering a healthy CAGR of around 14.2% during 2025–2034. This growth surge reflects the rapid integration of AI voice technologies across entertainment, customer service, content creation, gaming, and virtual assistant ecosystems. With hyper-realistic synthetic voices becoming mainstream, brands and creators are increasingly shifting toward AI-driven voice production to enhance personalization, speed, and scalability in digital communication.
Get More Information about this report -
Request Free Sample ReportBehind this expansion is the rapid maturation of neural text-to-speech (TTS), voice cloning, and expressive prosody control that elevate synthetic speech from functional to human-like. Market size has scaled from early pilot deployments to enterprise-grade rollouts across contact centers, media localization, assistive technologies, and embedded automotive and consumer devices. In 2023, North America led with a 37.9% revenue share (USD 0.56 billion), reflecting strong enterprise AI adoption and hyperscale cloud availability; however, the addressable base continues to broaden as unit economics improve and latency falls below real-time thresholds for many interactive applications.
Growth is propelled by both demand- and supply-side tailwinds. On the demand side, brands are operationalizing voice as an always-on interface to lower service costs and lift conversion, while public-sector and healthcare stakeholders deploy synthetic speech to expand accessibility and multilingual reach. On the supply side, advances in large speech models, neural vocoders, and diffusion-based synthesis enhance naturalness, speaker fidelity, and low-resource language support, while model compression and on-device accelerators reduce inference cost per minute. Nevertheless, the industry faces constraints: rights management and consent for voice likenesses, deepfake misuse risks, evolving compliance under privacy and AI-risk frameworks, and the need for watermarking, provenance, and speaker verification. Data quality, domain adaptation, and edge-case performance (e.g., code-switching, medical terminology) remain technical hurdles.
Innovation cycles are reshaping adoption patterns. Zero-shot and few-shot voice cloning are shortening time-to-value; SSML++ toolchains and emotion/style tokens are enabling brand-consistent voices at scale; and hybrid cloud/edge architectures are balancing security with sub-200 ms response expectations. Generative dialog and multimodal orchestration are emerging adjacencies, integrating TTS with ASR and LLMs to deliver closed-loop conversational agents.
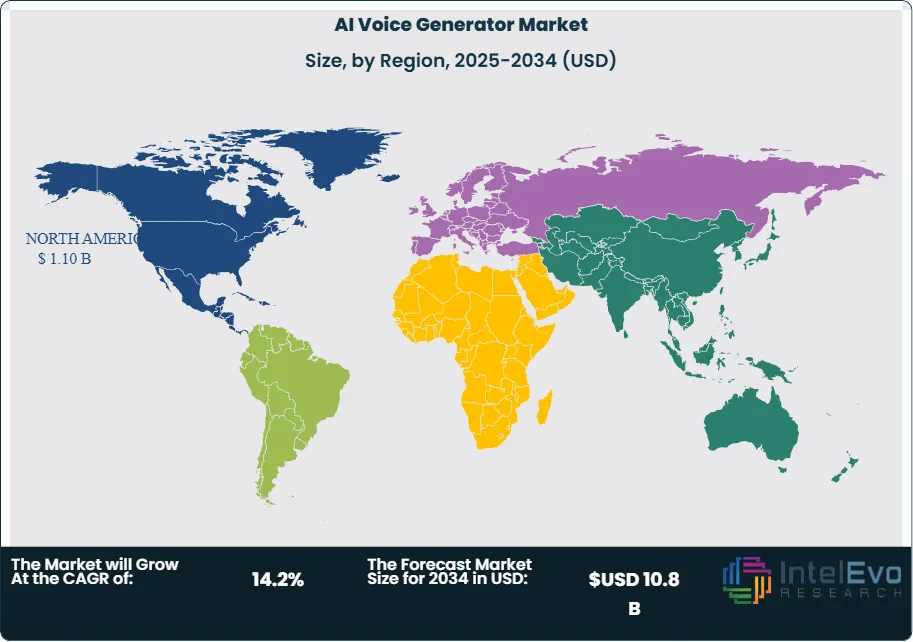
Regionally, North America will retain outsize influence given ecosystem depth, yet Asia–Pacific is poised for the fastest growth as smartphone penetration, gaming, and e-commerce fuel localized voice experiences across India, Southeast Asia, Japan, and South Korea. Europe’s stringent data-protection and AI governance are creating a premium for compliant, watermark-ready solutions, while investment attention is rising in the Middle East for smart-city, telco, and public-service deployments. For investors, hotspots include enterprise-grade platforms with consent and governance built-in, verticalized medical and education voices, and edge-optimized models for automotive, wearables, and retail endpoints.
, By Deployment Mode (Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning), By End-Use Industry (Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce) Industry Regions & Key Players – Market Structure, Innovation Trends, Competitive Strategies & Forecast 2025–2034")
Key Takeaways
- Market Growth: The AI Voice Generator market was valued at USD 2.9 billion in 2024 and is projected to reach USD 10.8 billion by 2034, reflecting a 14.2% CAGR. Expansion is underpinned by CX automation, content localization, and accessibility mandates across public and private sectors.
- Technology (Text-to-Speech): Text-to-Speech (TTS) held 70.5% share in 2023, cementing its position as the default engine for scalable, multilingual voice output. Advanced neural vocoders and expressive prosody controls are keeping TTS ahead of voice cloning, though the latter is set to outpace the market with high-teens CAGR as brand and creator use cases scale.
- Product Type (Software): Software platforms captured 66% share in 2023, driven by API-first offerings from leaders such as Microsoft Azure Cognitive Services, Google Cloud TTS, Amazon Polly, OpenAI, and ElevenLabs. Subscription models and prebuilt voices shorten deployment cycles versus services-heavy custom builds.
- Driver: Cloud-based deployment accounted for 74.1% of 2023 revenue, enabling elastic scaling, rapid integration, and global reach for contact centers, media localization, and e-commerce. Broad SDK support and pay-as-you-go inference are accelerating time-to-value for enterprise rollouts.
- Restraint: Voice rights, consent, and deepfake mitigation requirements increase compliance overhead, adding an estimated 10–15% to implementation costs and extending procurement by 2–3 months in regulated sectors. Data-residency and IP protection concerns also push some buyers toward hybrid or on-prem architectures.
- Opportunity: Asia–Pacific is positioned as the fastest-growing region, with an expected ~18–20% CAGR through 2033, supported by gaming, short-form video, and e-commerce localization. APAC could account for ~35% of incremental market expansion (~USD 1.7 billion of the 2023–2033 increase).
- Trend: Zero-/few-shot voice cloning, emotion/style tokens, and watermarking/provenance features are moving into enterprise-grade roadmaps. Vendors are converging TTS with ASR and LLMs to deliver closed-loop conversational agents, while early hybrid edge deployments target sub-200 ms latency for automotive, wearables, and retail endpoints.
- Regional Analysis: North America led with 37.9% share (USD ~0.56 billion) in 2023, supported by hyperscale cloud and early enterprise adoption. Europe is expanding at mid-teens growth under stringent AI/data protection regimes, while APAC’s faster trajectory makes India, Southeast Asia, Japan, and South Korea near-term investment hotspots.
Component Analysis Analysis
Software remains the economic center of the AI Voice Generator stack entering 2025, anchored by API-first platforms and model marketplaces. Building on its >66% revenue share in 2023, software is expected to sustain a clear majority through the medium term as enterprises standardize on cloud SDKs, pre-trained voice libraries, and toolchains for prosody control, SSML, and multilingual delivery. Leading providers (e.g., Microsoft, Google, Amazon, OpenAI, ElevenLabs) continue to compress latency and inference cost per minute, expanding viable use cases from IVR containment to broadcast-grade narration and dynamic advertising.
Services—covering custom voice creation, domain adaptation, data labeling, and governance—are scaling in tandem with enterprise rollouts. Growth is concentrated in regulated verticals and brands seeking consented “owned voices,” watermarking, and provenance pipelines. As AI risk management and accessibility mandates tighten, service revenues increasingly bundle compliance, security reviews, and integration with identity/consent systems, supporting higher attach rates despite software’s dominance.
Deployment Mode Analysis
Cloud remains the default delivery model, retaining the 74.1% share recorded in 2023 and benefiting from elastic scaling, global reach, and pay-as-you-go pricing that compress time-to-value for omnichannel CX and media localization. Multi-region endpoints and edge accelerators are pushing round-trip synthesis toward sub-200 ms for interactive agents, while managed model updates sustain accuracy and language coverage without customer-side ML ops.
On-premise and hybrid deployments are growing where data sovereignty, low-latency local processing, or IP control is non-negotiable—notably in healthcare, financial services, and public sector. Expect hybrid patterns (local inference + cloud orchestration) to capture a larger slice of new enterprise deals through 2027 as buyers balance residency, cost, and latency, and as on-device runtimes (e.g., for automotive infotainment and wearables) enable offline or privacy-preserving experiences.
By Type Analysis
Text-to-Speech (TTS) remains the market’s cornerstone, accounting for 70.5% share in 2023 and expanding with improvements in neural vocoders, expressive style tokens, and low-resource language support. TTS underpins scaled workloads—contact centers, assistive tech, e-learning, and media narration—where consistency, latency, and cost per output minute are critical procurement metrics.
Voice cloning is the fastest-rising subsegment as creators, broadcasters, and enterprises adopt consented, brand-safe synthetic voices for localization, advertising, and personalized content. While smaller today than TTS, cloning is set to outpace the total market’s ~15.6% CAGR as watermarking, speaker verification, and rights-management tooling mature, shifting pilots into production for multilingual campaigns and dynamic, identity-anchored experiences.
By End-Use Industry Analysis
Media & Entertainment leads with a 32.8% share (2023), propelled by localization, dubbing, audiobooks, gaming NPCs, and rapid trailer/spot creation. Studios and streaming platforms are moving toward “localize-by-default” strategies using TTS/cloning to lift engagement in non-English markets while preserving brand voice and turnaround times.
Beyond media, adoption is diversifying. BFSI, IT & telecom, and retail & e-commerce deploy synthetic voice to increase IVR containment, enable conversational commerce, and standardize tone across regions. Healthcare applications span accessibility, clinician guidance, and patient engagement, while automotive integrates embedded assistants for hands-free control. These sectors collectively accelerate volume growth—even as governance, consent management, and bias testing become standard buying criteria.
By Region
North America retains leadership with 37.9% share and ~USD 0.56 billion revenue in 2023, supported by hyperscale cloud footprints, early enterprise budgets, and an active startup ecosystem. Europe is scaling under stricter AI and data-protection regimes, favoring vendors with watermark-ready, provenance-rich pipelines and multilingual coverage for major EU markets.
Asia Pacific is the fastest-growing opportunity through 2025–2030, underpinned by mobile-first consumers, gaming and creator economies, and e-commerce localization across India, Southeast Asia, Japan, and South Korea; growth is widely expected to track high-teens CAGR, outpacing the global average. Latin America is emerging in customer service and media localization, while the Middle East & Africa sees rising investment tied to smart-city, telco, and public-service use cases—often favoring hybrid deployments to meet residency and Arabic-language performance requirements.
Get More Information about this report -
Request Free Sample ReportMarket Key Segments
By Component
- Software
- Services
By Deployment Mode
- Cloud-Based
- On-Premise
By Type
- Text-to-Speech
- Voice Cloning
By End-Use Industry
- Media & Entertainment
- BFSI
- IT & Telecommunications
- Healthcare
- Automotive
- Retail and E-commerce
- Other End-Use Industries
By Regions
- North America
- Latin America
- East Asia And Pacific
- Sea And South Asia
- Eastern Europe
- Western Europe
- Middle East & Africa
| Report Attribute | Details |
| Market size (2024) | USD 2.9 B |
| Forecast Revenue (2034) | USD 10.8 B |
| CAGR (2024-2034) | 14.2% |
| Historical data | 2018-2023 |
| Base Year For Estimation | 2024 |
| Forecast Period | 2025-2034 |
| Report coverage | Revenue Forecast, Competitive Landscape, Market Dynamics, Growth Factors, Trends and Recent Developments |
| Segments covered | By Component, Software, Services, By Deployment Mode, Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning, By End-Use Industry, Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce, Other End-Use Industries |
| Research Methodology |
|
| Regional scope |
|
| Competitive Landscape | ElevenLabs, IBM Corporation, Amazon Web Services, Inc., Listnr AI, Speechelo, Google LLC, WellSaid Labs, Microsoft Corporation, Samsung Group, Speechki, Respeecher, Synthesia, Baidu, Inc., Cerence Inc., CereProc Ltd., Other Key Players |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Pricing and Purchase Options | Avail customized purchase options to meet your exact research needs. We have three licenses to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF). |
, By Deployment Mode (Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning), By End-Use Industry (Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce) Industry Regions & Key Players – Market Structure, Innovation Trends, Competitive Strategies & Forecast 2025–2034")
, By Deployment Mode (Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning), By End-Use Industry (Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce) Industry Regions & Key Players – Market Structure, Innovation Trends, Competitive Strategies & Forecast 2025–2034")
, By Deployment Mode (Cloud-Based, On-Premise, By Type, Text-to-Speech, Voice Cloning), By End-Use Industry (Media & Entertainment, BFSI, IT & Telecommunications, Healthcare, Automotive, Retail and E-commerce) Industry Regions & Key Players – Market Structure, Innovation Trends, Competitive Strategies & Forecast 2025–2034")

Select Licence Type
Connect with our sales team
Why IntelEvoResearch
100%
Customer
Satisfaction
24x7+
Availability - we are always
there when you need us
200+
Fortune 50 Companies trust
IntelEvoResearch
80%
of our reports are exclusive
and first in the industry
100%
more data
and analysis
1000+
reports published
till date
