
- Home
- Industries
 Aerospace And Defence
Aerospace And Defence
 Agriculture
Agriculture
 Automotive And Transportation
Automotive And Transportation
 Banking And Finance
Banking And Finance
 Business
Business
 Chemicals And Materials
Chemicals And Materials
 Consumer And Retail
Consumer And Retail
 Electronics And Semiconductors
Electronics And Semiconductors
 Food And Beverages
Food And Beverages
 Machinery & Equipments
Machinery & Equipments
 Manufacturing And Construction
Manufacturing And Construction
 Medical Devices
Medical Devices
 Others
Others
 Pharmaceuticals And Healthcare
Pharmaceuticals And Healthcare
 Power And Energy
Power And Energy
 Sports
Sports
 Technology
Technology
- Services
- News Room
- About us
- Contact Us
-
Generative AI in Testing Market Size, Trend | CAGR 34.2%
Global Generative AI in Testing Market Size, Share, Analysis Report Component (Software, Services), Deployment (Cloud, On-premises, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation, AI-Powered Test Maintenance, Predictive Quality Analytics, Technology, NL-to-Test, Agentic Orchestration, Vision & Model-Based UI Understanding, Retrieval-Augmented Testing, Test-Data Generators), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) Region and Key Players - Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends and Forecast 2025-2034

Report Overview
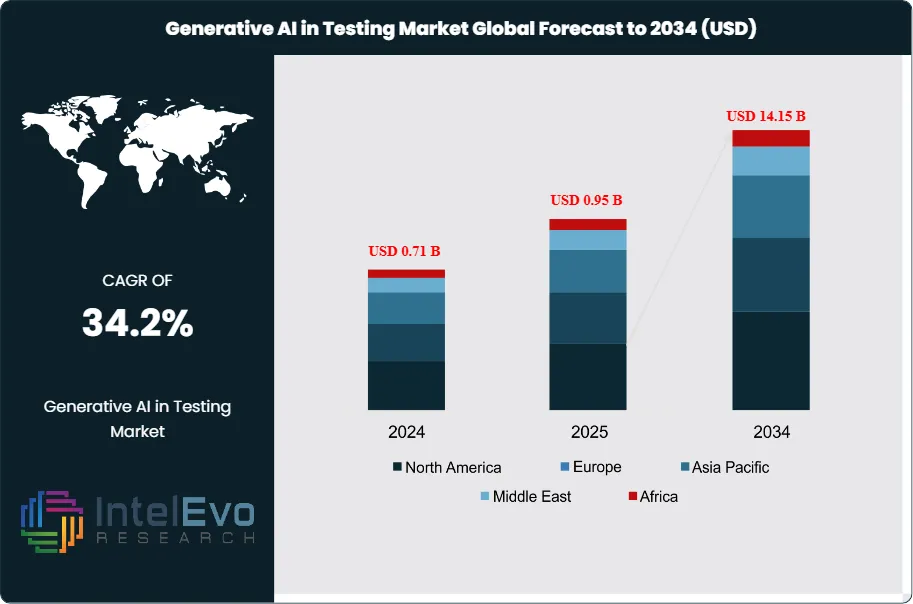
The Generative AI in Testing Market was valued at approximately USD 0.71 billion in 2024 and is projected to reach nearly USD 14.15 billion by 2034, driven by the rapid integration of AI-driven automation in software testing, continuous integration pipelines, and quality assurance processes. Based on the stated growth trajectory, the market size for 2025 is estimated at approximately USD 0.95 billion. From 2026 onward, the market is expected to expand at a compound annual growth rate (CAGR) of approximately 34.2% during 2026–2034, ultimately reaching around USD 14.15 billion by 2034.
Get More Information about this report -
Request Free Sample ReportAdoption is led by software (about 71%), with buyers preferring cloud delivery (around 79.8%) for speed, elastic capacity, and simpler updates. Among applications, automated test-case generation (roughly 29%) has the widest use because it turns plain language into runnable tests and lifts coverage with minimal scripting. Regionally, North America (near 40.8%) remains the reference market given mature cloud estates, early QA modernization, and strong developer tooling.
Inside teams, the operating model is changing. Natural-language authoring collapses backlog, synthetic data with guardrails exercises sensitive or long-tail scenarios, and self-healing repairs brittle flows as interfaces or APIs evolve. Predictive signals push regression toward high-risk code, shrinking runs while raising their hit rate. Around the platform, services wire capabilities into requirements, code and defect systems, and set prompt patterns, review checklists, and approval gates so generated assets are versioned and auditable. Cloud distribution helps rollouts move quickly; hybrid patterns keep restricted datasets local. Programs that treat governance as design—redaction, residency, model/version pinning, evidence capture—avoid stalls in security review and step steadily from pilot to everyday use.
By end use, traction is highest where release frequency and reliability are both non-negotiable, including IT and telecom, financial services, healthcare, and public services.
North America continues to lead production adoption; Asia Pacific shows the fastest momentum as digital-native firms convert trials into steady practice; Europe concentrates on privacy-safe coverage and explainability; Latin America and the Middle East & Africa scale through partner-led integrations and practical wins. Product direction is converging: copilots embedded in IDEs and pipelines, agent-based orchestration to link data setup, UI steps and API calls in one pass, and evaluation harnesses that grade outputs before they land in suites. The pragmatic path is clear: start in high-churn modules, stabilize flaky suites with self-healing and review gates, add synthetic data for sensitive flows, and track a short KPI set—authoring time, flaky-test rate, and escaped defects—to expand with confidence. Keep humans in the loop.
, Deployment (Cloud, On-premises, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation, AI-Powered Test Maintenance, Predictive Quality Analytics, Technology, NL-to-Test, Agentic Orchestration, Vision & Model-Based UI Understanding, Retrieval-Augmented Testing, Test-Data Generators), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) Region and Key Players - Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends and Forecast 2025-2034")
Key Takeaways
- Global Growth: The market rises from USD 0.71 billion (2024) to USD 14.17 billion (2034), at about 34.2% CAGR (2025–2034)—signaling steady multi-year expansion as GenAI moves from pilots into day-to-day QA.
- Component (Software): More than 71% share in 2024, underscoring platform-led buying and a tilt toward integrated toolchains rather than point solutions.
- Deployment (Cloud): Over 79.8% in 2024, reflecting preference for elastic capacity, rapid onboarding, and managed updates across environments.
- Application (Test Case Generation): More than 29% in 2024, showing that NL-to-test authoring delivers the clearest near-term payoff in speed and coverage.
- End Use (IT & Telecom): More than 34% in 2024, aligned with high release frequency, complex service stacks, and always-on reliability demands.
- Driver: Cloud-first LLMs in QA cut authoring time, widen coverage with synthetic data, and stabilize suites via self-healing and risk signals.
- Restraint: Data governance and in-region processing needs, plus flaky outputs without guardrails; integration and skills gaps slow scale.
- Opportunity: Regulated sectors and ERP/SaaS estates can use auditable generation and synthetic data to unlock previously untestable flows and shrink backlogs.
- Trend: Copilot features inside IDE/CI and agent-based orchestration linking data setup, UI, and API; regression shifts to risk-targeted runs.
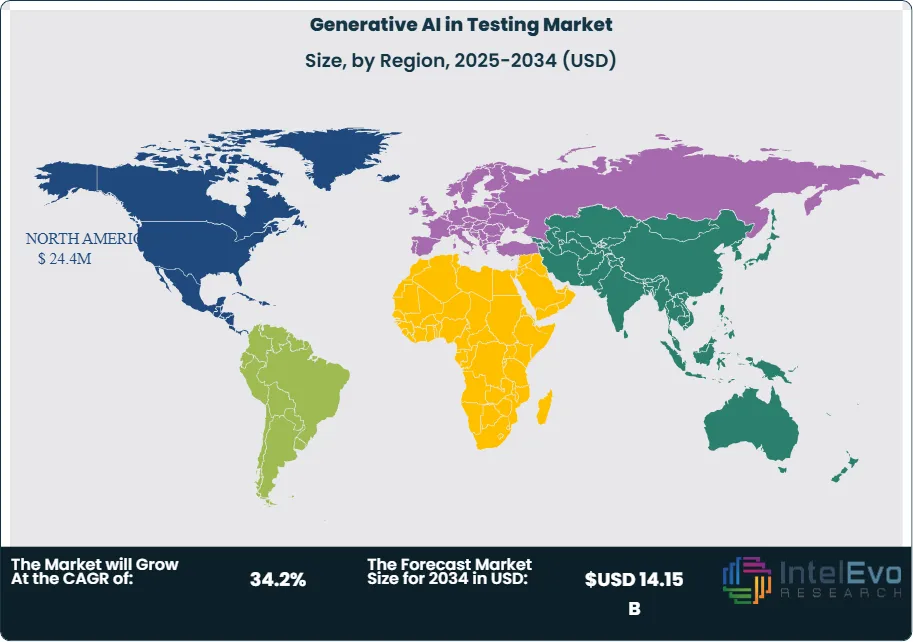
- Region: North America leads in 2025 at ~40.8% (~USD 24.4M); Asia Pacific is the fastest riser on strong public-cloud adoption.
Component Analysis
Spending is centered on the platform layer that brings generative AI into everyday testing work. In 2024, software accounted for about 71% of the market, which is roughly USD 35.2 million out of USD 48.9 million. These products turn plain language into executable tests, generate privacy-safe datasets for hard edge cases, and repair brittle steps when a user interface or an API changes. Because the tools connect to existing Agile and CI or CD routines and common IDEs, teams see practical gains: faster authoring, broader coverage, and more stable nightly runs without changing how engineers work.
Services sit around that core and make rollouts stick. With software at about 71%, the remaining 28% is services, or roughly USD 13.7 million in 2024. Typical work includes integrations with requirements, code, and defect systems, privacy and data-residency reviews, prompt and test-pattern standards, synthetic-data guardrails, and change management so the new flow is actually adopted. Deployment matters here. Cloud at about 81% converts to roughly USD 39.6 million delivered as managed or SaaS offerings, versus about USD 9.3 million on-premises. If we apply the same split within components, that maps to roughly USD 28.5 million for cloud software and about USD 11.1 million for cloud services today.
Deployment Analysis
Cloud remained the default choice in 2025, accounting for about four-fifths of total spend (≈79.8%). On a market of roughly USD 59.6 million in 2025, that equals around USD 48.2 million flowing to cloud delivery. Teams prefer it for elastic compute, quick provisioning, and managed updates that keep tools current without extra overhead. The pattern holds from startups to large enterprises. Lower upfront costs and no heavy in-house infrastructure make it easier to run large models and simulations, store test artifacts, and scale environments during peak test cycles. Frequent updates to AI capabilities and guardrails help keep testing flows effective as applications change through the sprint cadence.
On-premises and private cloud still matter where data is highly sensitive, residency rules are strict, or network control is essential. This is roughly the remaining 19% in 2025, equating to about USD 11.3 million. In practice, many programs take a hybrid approach: cloud for elastic authoring, analytics, and experimentation; local environments for restricted datasets, final validation, and latency-critical stages.
Application Analysis
In 2025, test case generation remained the largest application in generative AI for testing, at about 29% of total spend—around USD 16.7 million out of USD 59.6 million. Teams favor this area because natural language can be turned into executable tests quickly, cutting authoring time and reducing manual slip-ups. The approach also widens coverage. Models can propose scenarios that span inputs, user paths, and environments that are easy to miss when writing tests by hand. That helps complex systems catch more issues earlier and makes nightly runs more reliable.
The fit with Agile and CI/CD is strong. As features change sprint by sprint, fresh tests can be generated to match new behavior, while reviewers keep quality tight. The result is faster iteration with less scripting and a steadier pipeline from commit to release.
End-User Industry Analysis
In 2025, IT and Telecom led industry demand at about 34%, equal to around USD 20.3 million. Always-on services, heavy traffic, and security needs create pressure to test more, faster, and with fewer gaps. Generative tools help simulate varied network conditions and user interactions, produce privacy-safe data for sensitive flows, and maintain fragile paths as interfaces evolve. This combination improves reliability for high-volume services and supports stricter service-level goals.
Rising network complexity amplifies the case. With broader 5G rollouts and expanding IoT fleets, operators juggle more endpoints, protocols, and edge scenarios. GenAI-enabled testing helps spot potential failures earlier, stabilize releases, and keep customer experience smooth.
Regional Analysis
North America leads in 2025 with ~40.8% of global spend—about USD 24.4M out of ~USD 59.6M—driven by mature cloud estates, CI/CD-heavy engineering, and strong demand from finance, healthcare, and public services. The mix skews to cloud ~79.8% (~USD 19.8M) and software ~71% (~USD 17.6M), with test-case generation ~29% (~USD 6.8M) as the quickest win. This combination—governance-ready stacks, deep integrations, and short sprint cycles—keeps adoption practical: faster authoring, self-healing for brittle flows, synthetic data for sensitive paths, and risk-based analytics that focus regression on high-change areas. Asia Pacific is the fastest-growing region, propelled by digital-native software, gaming, and e-commerce and accelerating public-cloud use. As a sizing guide for 2025, each +1 percentage-point of global share ≈ USD 0.596M; even a +3–5pp upswing adds ~USD 1.8–3.0M in the year—showing how incremental share gains translate quickly into budget in APAC without needing large, slow reorganizations.
Get More Information about this report -
Request Free Sample ReportKey Market Segment
Component
• Software
• Services
Deployment
• Cloud
• On-premises / Private Cloud
• Hybrid
Application
• Automated Test Case Generation
• Intelligent Test Data Creation (Synthetic)
• AI-Powered Test Maintenance (Self-Healing)
• Predictive Quality Analytics
Technology / Approach
• NL-to-Test (Code-LLMs, Copilot-style)
• Agentic Orchestration (multi-step workflows)
• Vision & Model-Based UI Understanding
• Retrieval-Augmented Testing (RAG for requirements/coverage)
• Test-Data Generators (tabular, time-series, anonymization)
Organization Size
• Large Enterprises
• SMEs
End Use
• IT & Telecom
• BFSI
• Healthcare & Life Sciences
• Retail & eCommerce
• Manufacturing & Industrial
• Public Sector & Education
Region
• North America
• Europe
• Asia-Pacific
• Latin America
• Middle East & Africa
| Report Attribute | Details |
| Market size (2025) | USD 0.95 B |
| Forecast Revenue (2034) | USD 14.15 B |
| CAGR (2025-2034) | 34.2% |
| Historical data | 2018-2023 |
| Base Year For Estimation | 2024 |
| Forecast Period | 2025-2034 |
| Report coverage | Revenue Forecast, Competitive Landscape, Market Dynamics, Growth Factors, Trends and Recent Developments |
| Segments covered | Component (Software, Services), Deployment (Cloud, On-premises / Private Cloud, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation (Synthetic), AI-Powered Test Maintenance (Self-Healing), Predictive Quality Analytics, Technology / Approach, NL-to-Test (Code-LLMs, Copilot-style), Agentic Orchestration (multi-step workflows), Vision & Model-Based UI Understanding, Retrieval-Augmented Testing (RAG for requirements/coverage), Test-Data Generators (tabular, time-series, anonymization)), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) |
| Research Methodology |
|
| Regional scope |
|
| Competitive Landscape | Tricentis, Keysight (Eggplant), Applitools, Functionize, Parasoft, SmartBear, Mabl, Katalon, Sauce Labs, BrowserStack, LambdaTest, OpenText (Micro Focus), IBM, Microsoft, TestSigma, Diffblue |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Pricing and Purchase Options | Avail customized purchase options to meet your exact research needs. We have three licenses to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF). |
, Deployment (Cloud, On-premises, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation, AI-Powered Test Maintenance, Predictive Quality Analytics, Technology, NL-to-Test, Agentic Orchestration, Vision & Model-Based UI Understanding, Retrieval-Augmented Testing, Test-Data Generators), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) Region and Key Players - Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends and Forecast 2025-2034")
, Deployment (Cloud, On-premises, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation, AI-Powered Test Maintenance, Predictive Quality Analytics, Technology, NL-to-Test, Agentic Orchestration, Vision & Model-Based UI Understanding, Retrieval-Augmented Testing, Test-Data Generators), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) Region and Key Players - Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends and Forecast 2025-2034")
, Deployment (Cloud, On-premises, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation, AI-Powered Test Maintenance, Predictive Quality Analytics, Technology, NL-to-Test, Agentic Orchestration, Vision & Model-Based UI Understanding, Retrieval-Augmented Testing, Test-Data Generators), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education) Region and Key Players - Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends and Forecast 2025-2034")
Frequently Asked Questions
How big is the Generative AI in Testing Market?
Global Generative AI in Testing market is set to grow from USD 0.71B in 2024 to USD 14.15B by 2034,at a CAGR of 34.2% (2025–2034). Explore trends, opportunities and drivers.
Who are the major players in the Generative AI in Testing Market?
Tricentis, Keysight (Eggplant), Applitools, Functionize, Parasoft, SmartBear, Mabl, Katalon, Sauce Labs, BrowserStack, LambdaTest, OpenText (Micro Focus), IBM, Microsoft, TestSigma, Diffblue
Which segments covered the Generative AI in Testing Market?
Component (Software, Services), Deployment (Cloud, On-premises / Private Cloud, Hybrid), Application (Automated Test Case Generation, Intelligent Test Data Creation (Synthetic), AI-Powered Test Maintenance (Self-Healing), Predictive Quality Analytics, Technology / Approach, NL-to-Test (Code-LLMs, Copilot-style), Agentic Orchestration (multi-step workflows), Vision & Model-Based UI Understanding, Retrieval-Augmented Testing (RAG for requirements/coverage), Test-Data Generators (tabular, time-series, anonymization)), Organization Size (Large Enterprises, SMEs), End Use (IT & Telecom, BFSI, Healthcare & Life Sciences, Retail & eCommerce, Manufacturing & Industrial, Public Sector & Education)
How can this market research report help my business make strategic decisions?
Our market research reports provide actionable intelligence, including verified market size data, CAGR projections, competitive benchmarking, and segment-level opportunity analysis. These insights support strategic planning, investment decisions, product development, and market entry strategies for enterprises and startups alike.
How frequently is the data updated?
We continuously monitor industry developments and update our reports to reflect regulatory changes, technological advancements, and macroeconomic shifts. Updated editions ensure you receive the latest market intelligence.

Select Licence Type
Connect with our sales team
Generative AI in Testing Market
Published Date : 20 Aug 2025 | Formats :Why IntelEvoResearch
100%
Customer
Satisfaction
24x7+
Availability - we are always
there when you need us
200+
Fortune 50 Companies trust
IntelEvoResearch
80%
of our reports are exclusive
and first in the industry
100%
more data
and analysis
1000+
reports published
till date
