
- Home
- Industries
 Aerospace And Defence
Aerospace And Defence
 Agriculture
Agriculture
 Automotive And Transportation
Automotive And Transportation
 Banking And Finance
Banking And Finance
 Business
Business
 Chemicals And Materials
Chemicals And Materials
 Consumer And Retail
Consumer And Retail
 Electronics And Semiconductors
Electronics And Semiconductors
 Food And Beverages
Food And Beverages
 Machinery & Equipments
Machinery & Equipments
 Manufacturing And Construction
Manufacturing And Construction
 Medical Devices
Medical Devices
 Others
Others
 Pharmaceuticals And Healthcare
Pharmaceuticals And Healthcare
 Power And Energy
Power And Energy
 Sports
Sports
 Technology
Technology
- Services
- News Room
- About us
- Contact Us
-
Global Synthetic Data Generation Market Size & Forecast 2034 | CAGR 35.5%
Global Synthetic Data Generation Market Size, Share, Growth & Industry Analysis By Data Type (Tabular Data, Image & Video Data, Text Data, Audio Data), By Application (Model Training & Fine-Tuning, Privacy & Compliance, Testing & Quality Assurance, Data Sharing & Analytics), By Technology (GANs, VAEs, Diffusion Models, Differential Privacy), By Vertical (BFSI, Healthcare, Automotive, Retail, Government, Manufacturing, IT & Telecom) Industry Trends & Forecast 2026–2034

Report Overview
| Market Size (2025) | Forecast Value (2034) | CAGR (2026–2034) | Largest Region (2025) |
| USD 1.20 Billion | USD 18.50 Billion | 35.5% | North America, 44.2% |
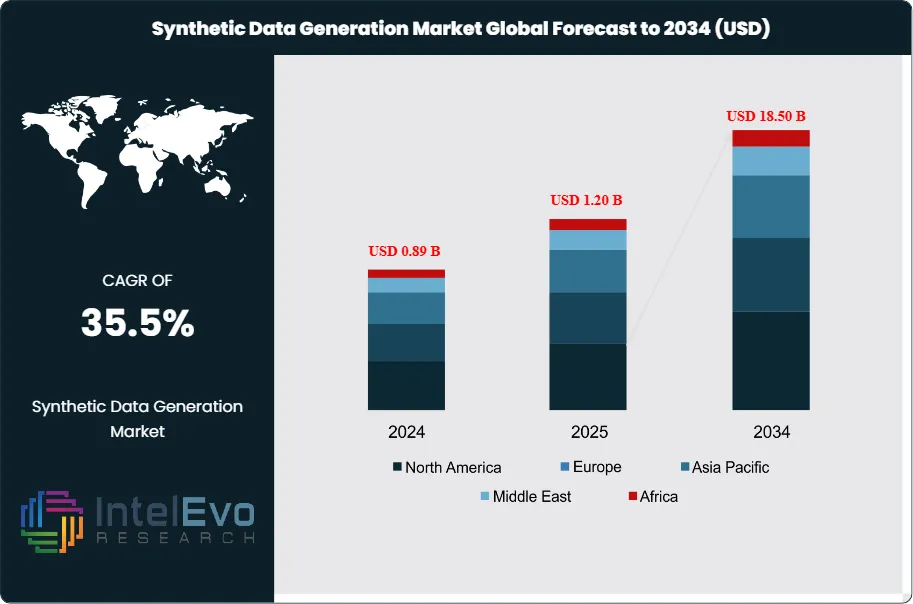
The Synthetic Data Generation Market was valued at approximately USD 0.89 Billion in 2024 and reached USD 1.20 Billion in 2025. The market is projected to grow to USD 18.50 Billion by 2034, expanding at a CAGR of 35.5% during the forecast period from 2026 to 2034. This represents an absolute dollar opportunity of USD 17.30 Billion over the analysis period. Synthetic data generation has emerged as a critical technological pillar for the expansion of artificial intelligence, providing a solution to the twin challenges of data scarcity and stringent privacy regulations. Current market assessment shows that as foundational models require increasingly massive datasets for fine-tuning, the availability of high-quality, human-annotated real-world data is reaching a point of exhaustion. Industry analysis indicates that synthetic alternatives now offer a viable path to maintain the velocity of model development while ensuring strict adherence to global privacy standards such as the GDPR and CCPA.
Get More Information about this report -
Request Free Sample ReportDemand and supply forces are currently shaped by the rapid adoption of generative AI architectures, particularly Variational Autoencoders (VAEs), Diffusion Models, and Generative Adversarial Networks (GANs). Supply-side evaluation suggests that specialized platforms are moving beyond simple tabular data to produce complex, high-fidelity unstructured formats, including 3D environments for autonomous vehicle training and synthetic medical records for pharmaceutical research. Regulatory influences have played a decisive role in market acceleration; as government agencies tighten controls on personal data usage, enterprises are pivoting toward synthetic datasets that carry zero risk of re-identification. This shift is particularly evident in the financial services and healthcare sectors, where the cost of data breaches has made the use of real-world production data increasingly risky.
Risk factors in the market involve the potential for model collapse, where AI systems trained exclusively on synthetic outputs begin to diverge from reality, losing the nuance of edge cases. However, technology effects including differential privacy and advanced reinforcement learning from human feedback (RLHF) are being integrated into generation pipelines to mitigate these risks. Regional highlights show that North America remains the primary investment hub, driven by the presence of major hyperscalers and a dense ecosystem of AI startups. Emerging investment hotspots are appearing in the Asia Pacific region, specifically in China and India, where large-scale digitalization and government-backed AI initiatives are creating massive demand for localized training data. Trade data and regulatory filings suggest that by 2030, a majority of data used for AI development will be synthetically generated, fundamentally restructuring the data acquisition economy.
, By Application (Model Training & Fine-Tuning, Privacy & Compliance, Testing & Quality Assurance, Data Sharing & Analytics), By Technology (GANs, VAEs, Diffusion Models, Differential Privacy), By Vertical (BFSI, Healthcare, Automotive, Retail, Government, Manufacturing, IT & Telecom) Industry Trends & Forecast 2026–2034")
Key Takeaways
- Market Growth: The Synthetic Data Generation Market is projected to grow from USD 1.20 Billion in 2025 to USD 18.50 Billion by 2034, representing a robust CAGR of 35.5% during the forecast period.
- Segment Dominance: The Tabular Data segment held the largest market share in 2025, accounting for 38.4% of total revenue, primarily due to high demand in BFSI for fraud detection and risk modeling.
- Segment Dominance: Based on application, the Model Training segment led the market with a 42.6% share in 2025, as enterprises seek to overcome real-world data scarcity in deep learning.
- Driver: Stringent data privacy regulations and the threat of massive compliance penalties are driving a 40.0% annual increase in synthetic data adoption for testing and development.
- Restraint: Quality verification and the risk of bias amplification in generated datasets represent a significant barrier, potentially impacting model accuracy if not strictly audited.
- Opportunity: The integration of synthetic data with digital twin technology in the manufacturing sector presents a USD 4.20 Billion untapped opportunity by 2034.
- Trend: Agentic AI systems are increasingly being used to autonomously generate and validate synthetic datasets, reducing the time-to-market for new AI applications by 30.0%.
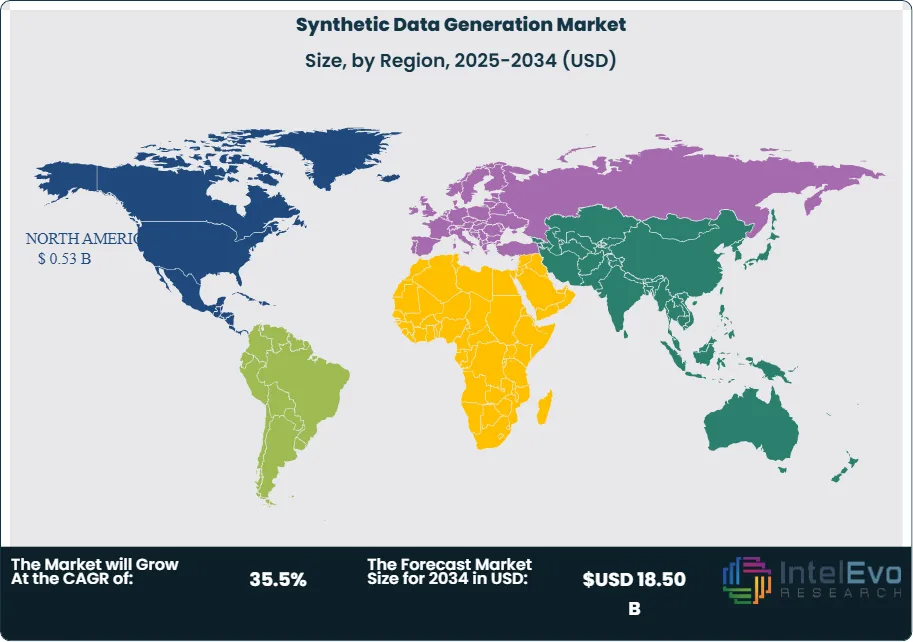
- Regional Analysis: North America is the leading region with a 44.2% share in 2025, valued at USD 0.53 Billion, supported by advanced enterprise infrastructure and R&D.
Competitive Landscape Overview
The Global Synthetic Data Generation Market is currently moderately fragmented, though it is showing signs of rapid consolidation as hyperscalers acquire niche specialists. Current market assessment indicates that the combined market share of the top four players was approximately 38.2% in 2025. Competition is technology-driven, with vendors differentiating through the fidelity of their data, the strength of their privacy-preserving algorithms, and their ability to integrate directly into existing MLOps pipelines. Recent competitive intensity has shifted toward platform-based competition, where providers offer end-to-end data generation and validation services. Strategic pivots among leaders involve moving from general-purpose data tools to vertical-specific solutions tailored for highly regulated industries.
Competitive Landscape Matrix
| Company Name | Headquarters | Market Position | Key Product/Solution | Geographic Strength | Recent Strategic Move |
| NVIDIA | USA | Leader | NVIDIA Omniverse | Global | Expanded 3D synthetic data tools for robotics in 2025 |
| MICROSOFT | USA | Leader | Azure AI Synthetic Data | North America | Integrated differential privacy in Azure OpenAI 2025 |
| GRETEL.AI | USA | Challenger | Gretel Navigator | Global | Launched LLM-based tabular data generator in mid-2025 |
| MOSTLY AI | Austria | Challenger | MOSTLY AI Platform | Europe | Partnered with major EU banks for DORA compliance 2025 |
| SYNTELLECT | USA | Niche Player | Syntho Engine | North America | Released specialized healthcare data modules in Jan 2026 |
| DATAGEN | Israel | Challenger | SimuLife | Global | Secured government contract for urban digital twins 2025 |
| HAZELCAST | USA | Niche Player | Hazelcast Data Sim | North America | Optimized real-time synthetic streaming for fintech 2025 |
| CVEDIA | UK | Niche Player | CVEDIA-RT | Europe | Focused on synthetic video for thermal imaging Jan 2026 |
| BETTERDATA | Singapore | Niche Player | Betterdata SaaS | Asia Pacific | Expanded market presence in India and Japan late 2025 |
| AI REVERIE | USA | Challenger | AirSim | Global | Launched high-fidelity aerial synthetic data tools 2025 |
By Data Type
The Synthetic Data Generation Market by data type is segmented into Tabular Data, Image and Video Data, Text Data, and Audio Data. Tabular data represented the dominant segment in 2025, accounting for 38.4% of total market revenue, valued at USD 0.46 Billion. Current market assessment shows that this segment is fueled by the financial services and retail industries, which rely on massive volumes of structured data for customer behavioral analysis and credit risk assessment. Synthetic tabular data allows these organizations to share datasets across departments and with third-party vendors without violating privacy protocols. Industry analysis indicates that the ability to generate statistically accurate tabular records has become a prerequisite for modern data science teams. Adoption of this data type is expected to remain high as banks modernize their legacy systems and require privacy-safe testing environments for core banking transformations.
Image and video data is the second-largest and fastest-growing segment, expected to reach a 32.5% share by 2034. In 2025, this segment was valued at USD 0.35 Billion. Demand is primarily driven by the automotive and aerospace industries, where high-fidelity visual data is required to train computer vision systems for autonomous navigation. Based on trade data and supply-chain evaluation, the cost of capturing and labeling real-world video data is nearly 10 times higher than generating synthetic equivalents. As virtual simulation technology matures, the fidelity of synthetic images has reached a point where it is indistinguishable from reality for neural network training purposes. This allows for the simulation of edge-case scenarios, such as rare weather events or complex traffic accidents, which are difficult to capture in the physical world.
By Application
In terms of application, the market is categorized into Model Training and Fine-tuning, Privacy and Compliance, Testing and Quality Assurance, and Data Sharing/Analytics. Model training and fine-tuning led the market in 2025 with a 42.6% share, worth USD 0.51 Billion. Current assessment indicates that the aggressive adoption of Large Language Models (LLMs) has created a data bottleneck. Synthetic data allows developers to augment their training sets with rare edge cases that are difficult to find in real-world observations. This application is vital for reducing bias in AI models, as synthetic generation can be used to balance datasets that are skewed by historical real-world prejudices. Furthermore, the ability to generate synthetic text data is helping firms train domain-specific models for legal and medical applications where original data is highly restricted.
Privacy and compliance represents the fastest-growing application segment, projected to grow at a CAGR of 37.2% through 2034. Valued at USD 0.32 Billion in 2025, this application is essential for organizations operating in the European Union and North America. Regulatory filings show that synthetic data is increasingly being used as a safe harbor for data processing under strict sovereignty laws. By replacing sensitive customer records with synthetic counterparts, enterprises can perform advanced analytics while remaining 100% compliant with evolving data protection mandates. This segment is benefiting from the emergence of privacy-preserving technologies that provide mathematical guarantees of anonymity, such as differential privacy integrated into generation engines.
By Vertical
Vertical segmentation of the Synthetic Data Generation Market includes Healthcare and Life Sciences, BFSI, Automotive, Retail and E-commerce, and Government and Defense. The BFSI sector accounted for the largest share in 2025 at 29.5%, generating USD 0.35 Billion in revenue. Financial institutions utilize synthetic data to train fraud detection systems, where real-world fraud examples are statistically rare but highly critical. Current industry assessment indicates that synthetic data usage in BFSI reduces the time required for data access approvals from weeks to minutes. This speed allows banks to iterate on product development and risk models with far greater frequency than was possible when reliant on anonymized production data.
Healthcare and life sciences followed with a 24.8% share, valued at USD 0.30 Billion in 2025. This vertical is highly dependent on synthetic data to share patient-level information for clinical research while maintaining HIPAA compliance. Synthetic patient records allow for multi-institutional studies that were previously impossible due to privacy restrictions. Automotive and manufacturing verticals are also significant contributors, utilizing synthetic data to simulate millions of driving miles and industrial failures, which would be too dangerous or expensive to recreate in the physical world. The shift toward software-defined vehicles is making synthetic testing environments a core component of the automotive supply chain.
Regional Analysis
North America
North America dominated the Synthetic Data Generation Market in 2025, capturing a 44.2% share with revenue reaching USD 0.53 Billion. Current market assessment indicates that the region’s leadership is sustained by a high concentration of AI research facilities and the headquarters of major technology providers. The United States market alone accounted for over 85% of regional revenue. Based on trade data, U.S. enterprises have the highest adoption rate of synthetic data for internal R&D, driven by the need to maintain a competitive edge in generative AI. Regulatory environment in the U.S., while fragmented, has seen federal agencies like the NIST encourage the use of synthetic data to enhance the robustness of AI safety frameworks. Investment trends show that venture capital for synthetic data startups in North America grew by 25.0% in 2025, focusing on companies that provide high-fidelity 3D simulation for the defense and robotics sectors.
Europe
Europe held a 26.5% market share in 2025, valued at USD 0.32 Billion. The region’s growth is primarily dictated by the most stringent data privacy laws in the world. Industry analysis shows that the EU AI Act has created a massive compliance market for synthetic data tools. Germany, the UK, and France are the top three contributors, with German manufacturing giants using synthetic data to power their Industry 4.0 initiatives. European organizations are increasingly viewing synthetic data not just as a training tool, but as a strategic asset for cross-border data collaboration. Current assessment suggests that the adoption of shared Data Spaces in Europe will further accelerate the demand for privacy-preserving synthetic datasets through 2034. The European healthcare sector is also a major driver, utilizing synthetic medical records to comply with GDPR while advancing personalized medicine.
Asia Pacific
The Asia Pacific region is expected to exhibit the fastest growth over the forecast period, with a CAGR of 38.5%. In 2025, the region held an 18.2% share, worth USD 0.22 Billion. Growth is concentrated in China, Japan, and India. China’s focus on autonomous driving and smart city infrastructure is a major driver, with the government providing significant support for synthetic data simulation platforms. India is emerging as a critical hub for data labeling and generation services, with major IT service providers integrating synthetic data into their digital transformation offerings. Current industry analysis indicates that as APAC countries develop their own data protection laws, the pivot toward synthetic alternatives will accelerate, particularly in the e-commerce and fintech verticals. Japan's aging population is also driving investment in healthcare AI, where synthetic data is used to augment limited geriatric clinical datasets.
Latin America and Middle East & Africa
Latin America represented 5.6% of the market in 2025, worth USD 0.07 Billion. Brazil and Mexico are the largest regional contributors, with adoption led by the financial services sector as neobanks seek to optimize their risk engines. The Middle East & Africa held a 5.5% share in 2025, valued at USD 0.06 Billion. In the Middle East, specifically the UAE and Saudi Arabia, synthetic data is being used as a core component of national AI strategies. These nations are investing in synthetic data to build localized LLMs that respect cultural and linguistic nuances without compromising the privacy of their citizens. Infrastructure development in the Gulf region is expected to provide significant tailwinds for the market as data sovereignty becomes a primary policy goal.
Get More Information about this report -
Request Free Sample ReportMarket Key Segments
By Data Type
- Tabular Data
- Image and Video Data
- Text Data
- Audio Data
By Application
- Model Training and Fine-tuning
- Privacy and Compliance
- Testing and Quality Assurance
- Data Sharing and Analytics
By Technology
- Generative Adversarial Networks (GANs)
- Variational Autoencoders (VAEs)
- Diffusion Models
- Differential Privacy
By Vertical
- BFSI
- Healthcare and Life Sciences
- Automotive
- Retail and E-commerce
- Government and Defense
- Manufacturing
- IT and Telecommunications
Regional Analysis and Coverage
- North America
- Latin America
- East Asia And Pacific
- Sea And South Asia
- Eastern Europe
- Western Europe
- Middle East & Africa
| Report Attribute | Details |
| Market size (2025) | USD 1.20 B |
| Forecast Revenue (2034) | USD 18.50 B |
| CAGR (2025-2034) | 35.5% |
| Historical data | 2021-2024 |
| Base Year For Estimation | 2025 |
| Forecast Period | 2026-2034 |
| Report coverage | Revenue Forecast, Competitive Landscape, Market Dynamics, Growth Factors, Trends and Recent Developments |
| Segments covered | By Data Type, (Tabular Data, Image and Video Data, Text Data, Audio Data), By Application, (Model Training and Fine-tuning, Privacy and Compliance, Testing and Quality Assurance, Data Sharing and Analytics), By Technology, (Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Diffusion Models, Differential Privacy), By Vertical, (BFSI, Healthcare and Life Sciences, Automotive, Retail and E-commerce, Government and Defense, Manufacturing, IT and Telecommunications) |
| Research Methodology |
|
| Regional scope |
|
| Competitive Landscape | NVIDIA, MICROSOFT, GRETEL.AI, MOSTLY AI, SYNTELLECT, DATAGEN, HAZELCAST, CVEDIA, BETTERDATA, AI REVERIE, SYNTHO, TONIC.AI, DATA CELESTE, FACTUAL.AI, Others |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Pricing and Purchase Options | Avail customized purchase options to meet your exact research needs. We have three licenses to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF). |
, By Application (Model Training & Fine-Tuning, Privacy & Compliance, Testing & Quality Assurance, Data Sharing & Analytics), By Technology (GANs, VAEs, Diffusion Models, Differential Privacy), By Vertical (BFSI, Healthcare, Automotive, Retail, Government, Manufacturing, IT & Telecom) Industry Trends & Forecast 2026–2034")
, By Application (Model Training & Fine-Tuning, Privacy & Compliance, Testing & Quality Assurance, Data Sharing & Analytics), By Technology (GANs, VAEs, Diffusion Models, Differential Privacy), By Vertical (BFSI, Healthcare, Automotive, Retail, Government, Manufacturing, IT & Telecom) Industry Trends & Forecast 2026–2034")
, By Application (Model Training & Fine-Tuning, Privacy & Compliance, Testing & Quality Assurance, Data Sharing & Analytics), By Technology (GANs, VAEs, Diffusion Models, Differential Privacy), By Vertical (BFSI, Healthcare, Automotive, Retail, Government, Manufacturing, IT & Telecom) Industry Trends & Forecast 2026–2034")
Frequently Asked Questions
How big is the Synthetic Data Generation Market?
Global Synthetic data generation market valued at USD 0.89B in 2024, reaching USD 18.5B by 2034, growing at a CAGR of 35.5% from 2026–2034.
Who are the major players in the Synthetic Data Generation Market?
NVIDIA, MICROSOFT, GRETEL.AI, MOSTLY AI, SYNTELLECT, DATAGEN, HAZELCAST, CVEDIA, BETTERDATA, AI REVERIE, SYNTHO, TONIC.AI, DATA CELESTE, FACTUAL.AI, Others
Which segments covered the Synthetic Data Generation Market?
By Data Type, (Tabular Data, Image and Video Data, Text Data, Audio Data), By Application, (Model Training and Fine-tuning, Privacy and Compliance, Testing and Quality Assurance, Data Sharing and Analytics), By Technology, (Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Diffusion Models, Differential Privacy), By Vertical, (BFSI, Healthcare and Life Sciences, Automotive, Retail and E-commerce, Government and Defense, Manufacturing, IT and Telecommunications)
How can this market research report help my business make strategic decisions?
Our market research reports provide actionable intelligence, including verified market size data, CAGR projections, competitive benchmarking, and segment-level opportunity analysis. These insights support strategic planning, investment decisions, product development, and market entry strategies for enterprises and startups alike.
How frequently is the data updated?
We continuously monitor industry developments and update our reports to reflect regulatory changes, technological advancements, and macroeconomic shifts. Updated editions ensure you receive the latest market intelligence.

Select Licence Type
Connect with our sales team
Synthetic Data Generation Market
Published Date : 09 Apr 2026 | Formats :Why IntelEvoResearch
100%
Customer
Satisfaction
24x7+
Availability - we are always
there when you need us
200+
Fortune 50 Companies trust
IntelEvoResearch
80%
of our reports are exclusive
and first in the industry
100%
more data
and analysis
1000+
reports published
till date
