
- Home
- Industries
 Aerospace And Defence
Aerospace And Defence
 Agriculture
Agriculture
 Automotive And Transportation
Automotive And Transportation
 Banking And Finance
Banking And Finance
 Business
Business
 Chemicals And Materials
Chemicals And Materials
 Consumer And Retail
Consumer And Retail
 Electronics And Semiconductors
Electronics And Semiconductors
 Food And Beverages
Food And Beverages
 Machinery & Equipments
Machinery & Equipments
 Manufacturing And Construction
Manufacturing And Construction
 Medical Devices
Medical Devices
 Others
Others
 Pharmaceuticals And Healthcare
Pharmaceuticals And Healthcare
 Power And Energy
Power And Energy
 Sports
Sports
 Technology
Technology
- Services
- News Room
- About us
- Contact Us
-
Synthetic Voice Market Size, Share and it Booms with 29.49% CAGR
Global Synthetic Voice Market Size, Share, Analysis Report By Component (Service, Solution), Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) Industry Region & Key Players-Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends & Forecast 2025-2034

Report Overview
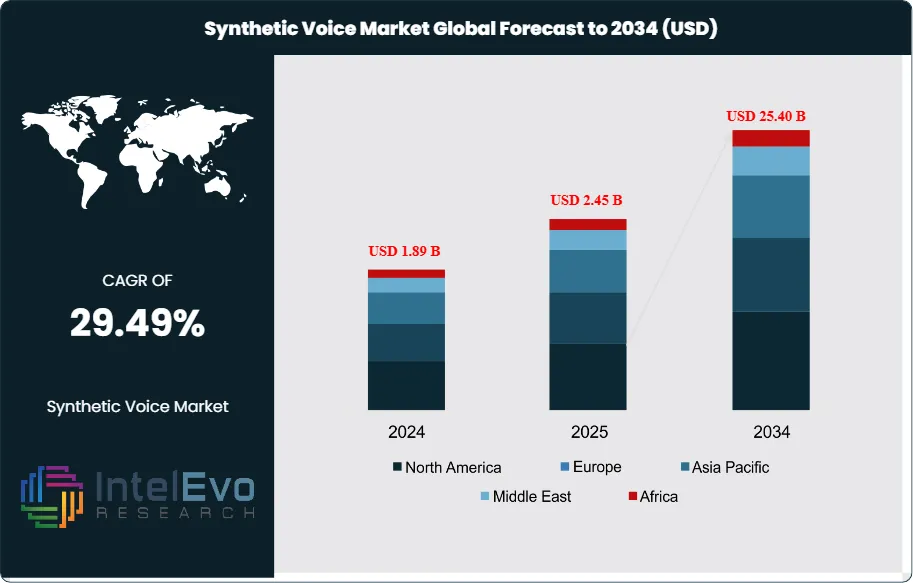
The Synthetic Voice Market size is expected to be worth around USD 25.40 Billion by 2034, from USD 1.89 Billion in 2024, growing at a CAGR of 29.49% during the forecast period from 2024 to 2034. The Synthetic Voice market is a transformative segment within the broader artificial intelligence and voice technology ecosystem, encompassing advanced AI-powered systems that generate human-like speech from text input using sophisticated neural networks and machine learning algorithms. Synthetic voice systems enable organizations to create natural-sounding audio content, voice assistants, and interactive experiences without requiring human voice actors or recording sessions.
Get More Information about this report -
Request Free Sample ReportThese platforms leverage deep learning technologies including neural text-to-speech (TTS), voice cloning, and speech synthesis to produce high-quality, customizable voices that can speak multiple languages, convey emotions, and adapt to specific brand requirements. The growing demand for voice-enabled applications, accessibility solutions, and cost-effective content creation is driving explosive growth in the synthetic voice market globally. Such systems are increasingly integrated with customer service platforms, e-learning applications, and entertainment production workflows to provide scalable voice solutions that enhance user experiences while reducing operational costs.
Several factors influence the expansion and evolution of the synthetic voice market. The primary driver is the proliferation of voice-activated devices and applications that require natural-sounding speech synthesis for user interaction, from smart speakers and virtual assistants to automotive systems and mobile applications. The need for accessibility solutions that support visually impaired users and reading disabilities drives demand for high-quality text-to-speech systems that can deliver clear, engaging audio content across digital platforms. Additionally, advances in neural network architectures, voice cloning technologies, and real-time speech synthesis continue to enhance synthetic voice quality and capabilities, enabling more sophisticated applications and broader market adoption. The growing emphasis on multilingual content creation and global market reach creates opportunities for synthetic voice solutions that can produce authentic-sounding speech in multiple languages and regional accents. Cost-effectiveness compared to traditional voice actor recording and production makes synthetic voice solutions attractive to organizations seeking scalable audio content creation capabilities.
Regionally, the Synthetic Voice market shows dynamic growth patterns reflecting varying levels of AI adoption, digital content creation maturity, and regulatory frameworks affecting voice technology deployment. North America leads the market due to early adoption of AI technologies, substantial investment in voice interface development, and the presence of major technology companies creating foundational synthetic voice platforms. The region benefits from mature digital media ecosystems and sophisticated consumer acceptance of AI-generated content that supports market expansion. The Asia-Pacific region demonstrates rapid growth potential, particularly in China, Japan, and India, where mobile-first consumer behavior and digital entertainment expansion create substantial opportunities for synthetic voice applications. Europe maintains significant market presence through emphasis on accessibility compliance, multilingual content requirements, and privacy-conscious voice technology deployment that drives demand for transparent, consent-based synthetic voice solutions.
The COVID-19 pandemic significantly accelerated synthetic voice adoption by highlighting the critical importance of digital content creation capabilities that could support remote education, virtual events, and contactless customer service during unprecedented operational challenges. Organizations rapidly adopted synthetic voice solutions to create educational content, automated customer service responses, and marketing materials without requiring in-person recording sessions or voice actor coordination. The pandemic demonstrated the value of synthetic voice systems for maintaining content production schedules and communication consistency despite workforce limitations and social distancing requirements. Economic pressures during the pandemic also emphasized the cost-effectiveness of synthetic voice solutions compared to traditional voice production methods that require studio time, talent coordination, and extensive post-production work.
Geopolitical tensions and intellectual property considerations between major economies have created challenges affecting the synthetic voice market through technology transfer restrictions, data sovereignty requirements, and ethical concerns about voice cloning and deepfake applications that influence regulatory approaches and market development. Export controls on advanced AI technologies and concerns about misuse of voice synthesis for disinformation or fraud have led to increased scrutiny of synthetic voice applications and deployment restrictions in some markets. Data privacy regulations and voice biometric protection requirements complicate international deployment of voice cloning and personalization features that rely on personal voice data collection and processing. These dynamics encourage development of ethical AI frameworks and transparent voice technology practices that may strengthen long-term market adoption while addressing legitimate security and privacy concerns.
, Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) Industry Region & Key Players-Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends & Forecast 2025-2034")
Key Takeaways
- Market Growth: The Synthetic Voice Market is expected to reach USD 55.8 Billion by 2034, driven by AI advancement, accessibility requirements, and voice interface proliferation across applications.
- Component Dominance: Solutions dominate the synthetic voice market as organizations prioritize direct adoption of voice synthesis technologies to power applications like media, gaming, and accessibility.
- Deployment Mode Dominance: Cloud deployment leads as it offers scalability, cost efficiency, and real-time updates, making it the preferred mode for synthetic voice adoption across industries.
- Application Dominance: Digital games lead application adoption as synthetic voices enhance immersive experiences, interactive storytelling, and personalization for players worldwide.
- Industry Vertical Dominance: The media and entertainment industry leads the market as it relies heavily on synthetic voices for content creation, dubbing, narration, and personalized media experiences.
- Drivers: Key drivers accelerating growth include accessibility compliance requirements, content creation automation, and voice interface adoption that boost market expansion through improved user experiences.
- Restraints: Growth is hindered by ethical concerns about voice misuse, technical quality limitations for emotional expression, and integration complexities with existing content workflows.
- Opportunities: The market is positioned for expansion through opportunities like real-time voice synthesis, multilingual content automation, and personalized voice assistant development.
- Trends: Emerging trends including emotional voice synthesis, voice cloning democratization, and AI-powered voice acting are reshaping the market by enabling sophisticated voice applications.
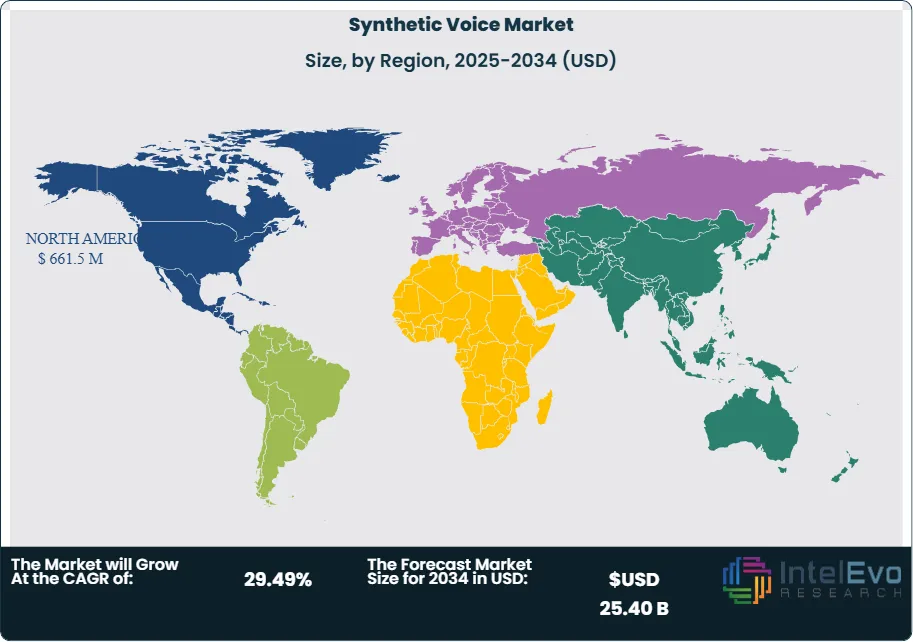
- Regional Analysis: North America leads with 42.3% market share due to AI technology leadership and digital content industry maturity. Asia-Pacific shows highest growth potential driven by mobile application expansion.
Component Analysis:
Solutions form the leading segment since enterprises primarily demand ready-to-deploy synthetic voice engines, APIs, and software tools to enhance user experiences. Companies across industries integrate these solutions into digital assistants, automated call systems, and entertainment platforms to improve interaction quality and engagement. Services, on the other hand, play a complementary but growing role by supporting customization, system integration, maintenance, and training for businesses adopting synthetic voice. Service providers offer consulting to tailor voices to brand identity or audience needs. While services continue to expand as enterprises require ongoing support, it is the core solution offerings that drive overall market growth. Their scalability, ability to accelerate digital engagement, and broad use across multiple verticals cement solutions as the largest contributor in this segment.
Deployment Mode Analysis:
Cloud-based deployments dominate because they provide businesses with flexibility, scalability, and lower upfront infrastructure costs. Enterprises increasingly prefer cloud platforms for synthetic voice since they allow access to pre-trained models, easy integration via APIs, and continuous upgrades without major IT investment. Cloud systems are highly favored in industries such as media, gaming, and customer service automation, which require real-time voice generation at scale. On-premise deployment remains relevant where data privacy, security, or regulatory compliance is paramount, such as in BFSI and healthcare. However, on-premise systems are costly, rigid, and require significant infrastructure maintenance, limiting their adoption to specialized users. By comparison, cloud-based systems enable global accessibility, reduced latency through distributed servers, and faster innovation cycles. This widespread utility ensures that cloud deployment continues to lead adoption in synthetic voice technology.
Application Analysis:
Digital Games Lead With Over 40% Market Share In Synthetic Voice Market, Digital gaming represents the largest application of synthetic voice since it enables developers to create dynamic characters, adaptive dialogues, and personalized user experiences without relying solely on manual recordings. Voice synthesis helps game studios reduce production costs while scaling voice support across multiple languages and regions. Accessibility stands as another significant application, using synthetic voices to assist visually impaired users, improve learning, and expand inclusivity in digital platforms. Chatbots and virtual assistants also rely heavily on synthetic voices to create natural, human-like interactions, improving customer service automation across industries. The “Others” category, including virtual events and online education, also applies voice synthesis to enhance engagement. While all applications benefit from synthetic voice, digital games lead because the industry demands creativity, cost optimization, and localized content that synthetic voices can deliver effectively and at scale.
Industry Vertical Analysis:
Media and entertainment dominate synthetic voice usage by integrating voice technologies in film dubbing, audiobook narration, advertising, and streaming platforms. Brands and content creators increasingly adopt synthetic voices to produce voiceovers quickly, reduce costs, and localize content for global audiences. Gaming, a subset of entertainment, further reinforces this demand through character development and immersive storytelling. Education is another significant vertical, using synthetic voice for interactive learning, e-learning modules, and accessibility for differently-abled students. BFSI and IT & telecom sectors deploy synthetic voices in customer support, virtual assistants, and fraud detection systems to enhance efficiency. Healthcare applies voice technologies for patient engagement, therapy, and accessibility-focused healthcare tools, while travel and hospitality adopt it for multi-language support and customer-facing applications. Although adoption spreads across industries, media and entertainment remain the leader due to their scale, demand for dynamic content, and rapid digital innovation.
Regional Analysis
North America Leads With nearly 35% Market Share In Synthetic Voice Market, North America maintains market leadership through established AI research institutions, substantial venture capital investment in voice technology startups, and early enterprise adoption of advanced speech synthesis technologies that create favorable conditions for synthetic voice market development and innovation. The region benefits from mature digital content industries, sophisticated consumer acceptance of AI-generated content, and regulatory frameworks that support innovation while addressing ethical concerns about synthetic voice applications. Cultural emphasis on accessibility and inclusive design drives demand for high-quality synthetic voice solutions that support diverse user needs and compliance requirements. The presence of major technology companies including Google, Amazon, Microsoft, and OpenAI provides access to cutting-edge synthetic voice platforms and comprehensive ecosystem support for application development and deployment.
Asia-Pacific represents the highest growth potential region, fueled by rapidly expanding mobile application markets, increasing digital content consumption, and substantial technology sector investment that creates significant opportunities for voice-enabled applications and services. The region's diverse linguistic landscape and cultural contexts drive demand for multilingual synthetic voice systems and localized voice models that can accurately represent regional accents and speaking patterns. Countries including China, Japan, and India demonstrate accelerating adoption as entertainment companies, e-learning platforms, and customer service organizations invest in voice automation capabilities to scale operations and improve user experiences. Government digital transformation initiatives and smart city development programs create additional opportunities for synthetic voice applications in public services and citizen engagement platforms.
Europe demonstrates strong growth driven by stringent accessibility regulations, multilingual content requirements, and emphasis on ethical AI deployment that favor transparent, privacy-compliant synthetic voice solutions over less regulated alternatives. The region's GDPR framework and consumer protection emphasis create demand for synthetic voice platforms that can provide personalization while maintaining strict privacy controls and user consent management. Cultural preferences for authentic, high-quality content drive adoption of advanced neural synthesis technologies that can produce natural-sounding speech in multiple European languages and regional variations.
Get More Information about this report -
Request Free Sample ReportKey Market Segment
Component
- Service
- Solution
Deployment Mode
- Cloud
- On-premise
Application
- Chatbots and Assistants
- Digital Games
- Accessibility
- Others
Industry Vertical
- Healthcare
- BFSI
- IT and Telecom
- Travel and Hospitality
- Education
- Media and Entertainment
- Others
Region:
- North America
- Europe
- Asia-Pacific
- Latin America
- Middle East & Africa
| Report Attribute | Details |
| Market size (2025) | USD 2.45 B |
| Forecast Revenue (2034) | USD 25.40 B |
| CAGR (2025-2034) | 29.49% |
| Historical data | 2018-2023 |
| Base Year For Estimation | 2024 |
| Forecast Period | 2025-2034 |
| Report coverage | Revenue Forecast, Competitive Landscape, Market Dynamics, Growth Factors, Trends and Recent Developments |
| Segments covered | Component (Service, Solution), Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) |
| Research Methodology |
|
| Regional scope |
|
| Competitive Landscape | ElevenLabs, Google LLC, Amazon Web Services (Polly), Microsoft Corporation (Azure Cognitive Services), IBM Corporation (Watson Text to Speech), OpenAI (Voice Engine), Murf AI, Synthesia, Speechify, Resemble AI, Descript, Altered Studio, WellSaid Labs, ReadSpeaker, Acapela Group |
| Customization Scope | Customization for segments, region/country-level will be provided. Moreover, additional customization can be done based on the requirements. |
| Pricing and Purchase Options | Avail customized purchase options to meet your exact research needs. We have three licenses to opt for: Single User License, Multi-User License (Up to 5 Users), Corporate Use License (Unlimited User and Printable PDF). |
, Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) Industry Region & Key Players-Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends & Forecast 2025-2034")
, Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) Industry Region & Key Players-Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends & Forecast 2025-2034")
, Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others) Industry Region & Key Players-Industry Segment Overview, Market Dynamics, Competitive Strategies, Trends & Forecast 2025-2034")
Frequently Asked Questions
How big is the Synthetic Voice Market?
The Synthetic Voice Market will surge from USD 1.89B in 2024 to USD 25.40B by 2034, growing at a massive CAGR of 29.49%. Explore key drivers and future trends now!
Who are the major players in the Synthetic Voice Market?
ElevenLabs, Google LLC, Amazon Web Services (Polly), Microsoft Corporation (Azure Cognitive Services), IBM Corporation (Watson Text to Speech), OpenAI (Voice Engine), Murf AI, Synthesia, Speechify, Resemble AI, Descript, Altered Studio, WellSaid Labs, ReadSpeaker, Acapela Group
Which segments covered the Synthetic Voice Market?
Component (Service, Solution), Deployment Mode (Cloud, On-premise), Application (Chatbots and Assistants, Digital Games, Accessibility, Others), Industry Vertical (Healthcare, BFSI, IT and Telecom, Travel and Hospitality, Education, Media and Entertainment, Others)
How can this market research report help my business make strategic decisions?
Our market research reports provide actionable intelligence, including verified market size data, CAGR projections, competitive benchmarking, and segment-level opportunity analysis. These insights support strategic planning, investment decisions, product development, and market entry strategies for enterprises and startups alike.
How frequently is the data updated?
We continuously monitor industry developments and update our reports to reflect regulatory changes, technological advancements, and macroeconomic shifts. Updated editions ensure you receive the latest market intelligence.

Select Licence Type
Connect with our sales team
Why IntelEvoResearch
100%
Customer
Satisfaction
24x7+
Availability - we are always
there when you need us
200+
Fortune 50 Companies trust
IntelEvoResearch
80%
of our reports are exclusive
and first in the industry
100%
more data
and analysis
1000+
reports published
till date
